Overview
The vclust package provides tools for weighted hierarchical clustering of variables, enabling users to group quantitative, categorical, or mixed variables into clusters based on their associations. Unlike traditional clustering of observations, this method focuses on variables, using weighted similarity measures such as squared Pearson correlations for numeric variables, weighted \eta^2 for numeric–factor pairs, and weighted canonical correlations for factor–factor pairs. Internally, the algorithm leverages FactoMineR (PCA, MCA, FAMD) to compute synthetic variables for clusters and uses an agglomerative approach based on ClustOfVar that minimizes the loss of homogeneity at each merge. This makes vclust ideal for dimensionality reduction and exploratory analysis in datasets with heterogeneous variable types and optional observation weights.
Installation
# Install the development version from bitbucket
remotes::install_bitbucket("bklamer/vclust")Usage
library(vclust)
# Example: Mixed data with weights
set.seed(123)
n <- 80
data <- data.frame(
num1 = rnorm(n),
num2 = rnorm(n) + 0.5 * rnorm(n),
num3 = rlnorm(n),
fac1 = factor(sample(letters[1:2], n, TRUE)),
fac2 = factor(sample(c("Low", "Medium", "High"), n, TRUE)),
fac3 = factor(sample(c("None", "Some", "All"), n, TRUE)),
weights = rexp(n)
)
# Perform weighted hierarchical clustering of variables
tree <- build_tree(data = data, weights = "weights")
# Plot dendrogram
plot(tree, main = "Hierarchical Clustering of Variables")
# Highlight partition into 2 clusters
rect.hclust(tree, k = 2)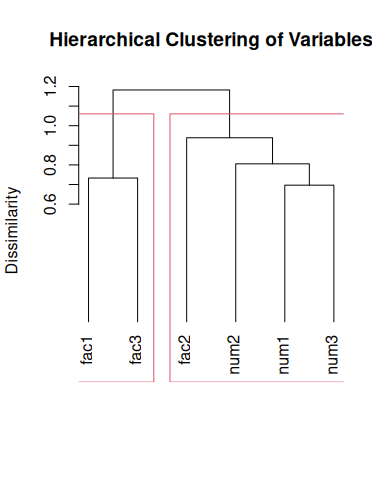
# Cut the tree into 2 clusters
partition <- cut_tree(tree, k = 2, cor_matrix = TRUE)
# Synthetic variables (first principal component scores)
head(partition$scores)
#> cluster_1 cluster_2
#> 1 -0.9417324 -1.4651794
#> 2 0.3807526 -0.9681873
#> 3 1.3983894 2.1196042
#> 4 -0.9417324 -1.6746250
#> 5 -0.9417324 -0.3305553
#> 6 1.3983894 1.4291443
# Correlation matrix for synthetic variables
partition$scores_cor_matrix
#> cluster_1 cluster_2
#> cluster_1 1.00000000 0.02213068
#> cluster_2 0.02213068 1.00000000
# Variable-level associations with synthetic variables
partition$vars
#> cluster variable squared_association association
#> 1 1 fac1 0.6334397 0.7958892
#> 2 1 fac3 0.6334397 0.7958892
#> 3 2 num3 0.5988382 0.7738464
#> 4 2 num1 0.4070317 0.6379903
#> 5 2 num2 0.3968098 -0.6299284
#> 6 2 fac2 0.1565695 0.3956887
# Correlation matrix for variables
head(partition$vars_cor_matrix)
#> $cluster_1
#> fac1 fac3
#> fac1 1.00000000 0.07122458
#> fac3 0.07122458 1.00000000
#>
#> $cluster_2
#> num1 num2 num3 fac2
#> num1 1.000000000 0.02820283 0.09195647 0.002360017
#> num2 0.028202833 1.00000000 0.07248153 0.010774156
#> num3 0.091956472 0.07248153 1.00000000 0.031310892
#> fac2 0.002360017 0.01077416 0.03131089 1.000000000
# Cluster homogeneity
partition$H
#> cluster_1 cluster_2
#> 1.266879 1.559249
# Proportion of total homogeneity explained by chosen cutpoint
partition$Hprop
#> [1] 0.2714152